树是一种很实用的数据结构,往往和查找,决策挂钩。提供对数级的时间复杂度。
而且树还有一点,因为它是结构递归的,所以它的很多算法,都可以用递归去实现。
这算是对《算法》这本书的总结,真心觉得这本书太好看了,不像算法导论那么难懂。
需要记住的是一颗树的深度,表示了它查找最深需要多深,而可以将所有节点的深度进行相加,再除以节点个数,来求出一个二叉查找树的平均高度。1979年,J.Robson证明了随机键构造的二叉查找树的平均高度为树的结点数的对数级别,随后L.Devroye证明了对于足够大的N,这个值趋近于2.99lgN。
二叉查找树被称为(BST),首先它是一颗二叉树,而且每个节点的左子树,键都比它小,每个节点的右子树,键都比它大。
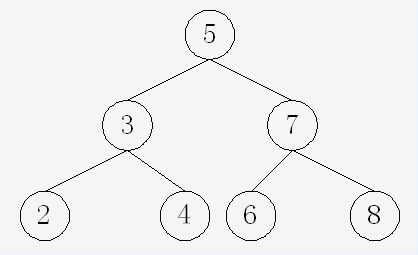
下面分别讲解其对应的接口:
查找:get
查找用递归实现非常方便:
1 | public value get(Key key){ |
试想如果一个二叉查找树,不是很平衡,已经“退化成”一个链表了,那么它查询的时间复杂度就变成了O(N),就像是一个对于链表的顺序查找。但如果对一个很平衡的二叉查找树进行查找。那么时间复杂度就是标准的对数级,lgN,就像是一个标准的二分查找。
一些归纳法推理的证明,最后得到二叉查找树的平均复杂度为 ~2lnN,约为1.39lgN,而二叉查找树中查找随机键的成本比二分查找高约39%。
插入:put
二叉查找树的另一个特性是插入的实现难度和查找差不多。
1 | public void pub(Key key, Value val){ |
删除表中对应的key值: delete
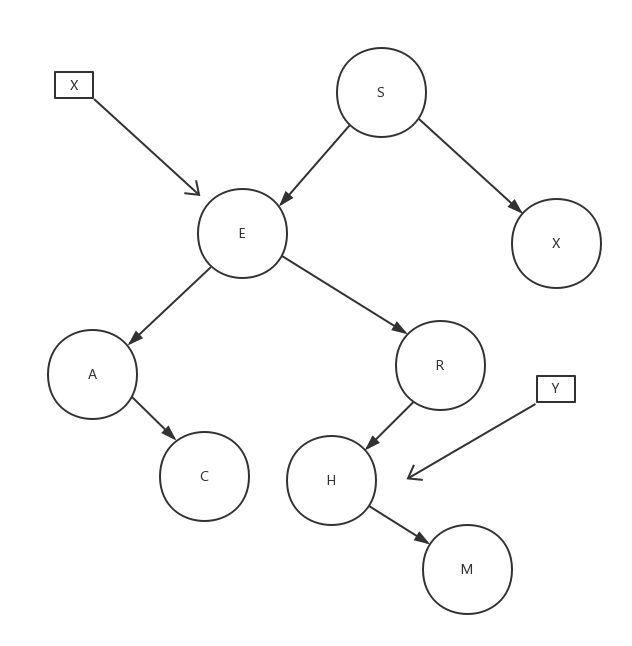
这个看上去是有点难,如果你删除的是一个叶子节点,还好说,删了就完了,但是如果是一颗非叶子节点呢,关键要保证如何删了此节点之后,剩余的节点要怎么办。
这种被称为Hibbard的方法,如果选定了要删除X,会先选择X右子树的最小节点(min),记为y,然后将X的左右子树分别挂到y上(X的左子树肯定比y小,因为y来源于X的右子树,X的右子树肯定比y大,因为y是X右子树的最小节点)。然后因为y是最小节点,所以y可能存在右子树,但只要把y的右子树上移到y原来的位置就行了。
这可能看上去很绕,这里我想到了一个思考方式。和大家分享一下。其实你只要“从失去的节点后,那些分支挂钩应该要挂到哪?”就明白了。
比如你删除了x,那对于x而言,将有3个位置,不知道要挂到哪里。分别就是指“上左右”。然后你找来了y来代替x的位置,这样“上左右”就被补充了,但是原来y的“上和右”又有了空缺,这样把“上和右”合并就好了。
最小键:min
递归的向左边不停的找到底就好了。
最大键: max
递归的向右边不停的找到底就好了。
小于等于key的最大键: floor
递归的向左找到小于等于key的最大键
大于等于key的最大键: ceiling
递归的向右找到大于等于key的最大键
小于key的键的数量: rank
这个可以用遍历的方式,遍历小于等于此key的左子树,然后计数。
键的数量: size
这个看上去需要遍历再计数,其实有些实现树的数据结构,会记下左右子树的个数,这样就可以直接看根节点左右子树的个数,然后+1就行了。
所有键的集合: keys
遍历一棵树,无论是先序遍历,中序遍历,后序遍历,递归的实现起来都非常简单。
[lo..hi]之间的所有键: keys(key lo, key hi)
这个实现方式也是基于遍历的,只不过要造一个队列,来讲符合条件的key扔入此队列中。最后返回此队列就行了。
树是否为空: isEmpty
这个没什么可说的,很简单。
所以二叉树虽然查找起来很快,但是如果不平衡,比如退化的像个链表,那么查找起来依旧不高效了。下一篇博客会介绍一种平衡二叉树的东西,来解决此问题。