首先要区分几个概念,Map这种东西,其实是一种统称的数据结构,翻译过来应该是映射表或者是关联数组。它的作用其实是提供一种映射来维护键值对,也就是说你可以通过键来找到值。而这些key组成的集合必须要是一个set。
然后再说实现,java的标准库中针对Map提供了好几种实现,比如所有哈希表实现的HashMap,还有基于红黑树实现的TreeMap。而在python中最常用的数据结构,dict也是哈希表实现的。
在java中一个对象要想能够作为Map的key,有一个关键的函数是equals,这个方法是用来判断两个对象是否相等的。如果你不重载此方法的时候,equals其实默认调用的 == 运算符。而等号运算符在堆中创建的对象其实是比较引用。所以对于字符串这样的对象,java重写了equals方法。这个方法对Map的用处是,Map使用此方法来确定两个对象是否相等,也就是说用Map的get方法获得数据的时候,其实是通过equals来比较key的。而如果是以HashMap实现的Map,那还需要一个关键的函数,就是hashCode,这个函数被称为散列函数,用来返回一个散列码,这就是对应哈希表的数据结构实现时的数组索引。
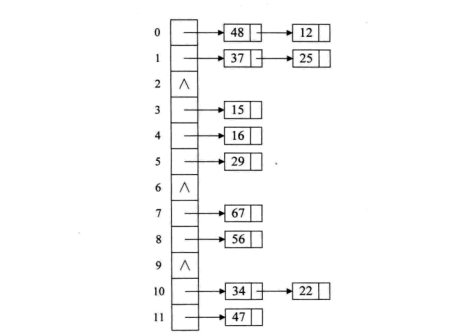
哈希表之所以查找速度是O(1),原因就是key存在一个数组中。
散列函数的好坏决定了key是否可以“散”的分布在桶(bucket)上,简单的实现方式有取余,还有a*key + b的实现方式。
但是散列码并不能保证唯一,所以从上图可以看到相同的散列值使用了链表进行连接(拉链法),这样对于相同散列值的元素,就不得不使用equal方法进行查找了。
python的哈希表
其实python的dict,就是使用hash表实现的。而且python基本上也是dict满天飞,初学python的时候一直不理解这个:
1 | >> d = { '1': '1', '2': '2', '3': '3'} |
后来才明白这个打印出来的顺序其实就是桶的顺序,所以当桶生长之后,这个顺序可能就变了。
那么python的桶是如何增长的呢?
貌似是根据一个什么概率算出来(挺复杂的一个证明过程),当使用的槽(slot),超过哈希表整个大小的2/3时,就开始扩张了。
什么样的元素可以作为dict的key?
在python源码的注释中有这样一句话:
1 | If a class does not define a __cmp__() method it should not define a __hash__() operation either; if it defines __cmp__() or __eq__() but not __hash__(), its instances will not be usable as dictionary keys. |
python的list就不能作为key,但是tuple就可以。而用户继承于object的对象,也可以作为字典的key。