其实提到树这种数据结构,你一定会和搜索联系起来,毕竟每次分支的决策就能过滤掉大半的选择,从而使解空间变得越来越小。有一种在文件系统很常用的树,那就是b树。
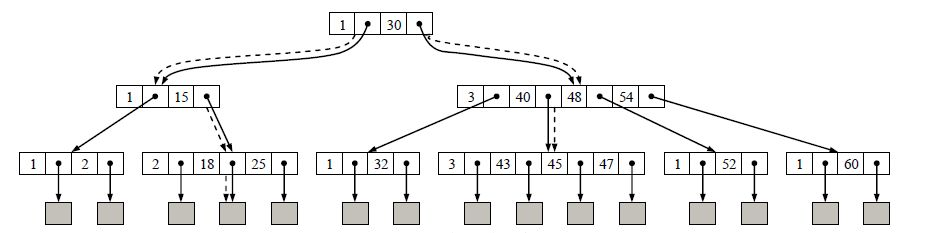
上面这张图就是一个b树的样子,b树的非终端节点,都是一个节点,可以存放一组信息,其结构可以定义为:(n, A0, K1, A1, K2, …. , Kn, An).其中n表示这个节点有几个关键字,而K就表示关键字,A表示指向子树节点的指针。那么从数据结构图就能明白,A0指向的节点都小于k1,A1指向的节点都大于k1小于k2.而且所有叶子节点都出现在同一层次上,并且不带信息(其实就是空指针)。
而这种被称为b树的树结构,关键的不同点是每个节点可有多个key和分叉使得你可以把节点的大小凑成某个数,比如接近磁盘一个块的大小(或整数倍)。因为磁盘的读写是一块一块进行的,所以这样做的话能够较高效率地IO。
下面两张图算是机械硬盘的主视图和俯视图了。其实没必要对机械硬盘过于深入的了解,只需要知道,我们的数据其实是存储于盘面的,当我的数据需要被读取或者写入的时候,都需要让磁头移动到那个盘面的那个位置,首先可以看到每一个盘面都都应一个磁头。盘面本身可以转动,而从第二张图也可以知道,磁头可以横向移动,从而触碰一个半径上的磁盘。就这样,我们可以访问n个盘面上的所有位置。但是你会发现,要随机访问一块数据非常慢,因为你要先确定数据在哪个盘面的哪个磁道的哪个扇区。然后先让磁盘旋转到磁头可以触碰的那个磁道,然后在让磁头移动到相应的扇区。
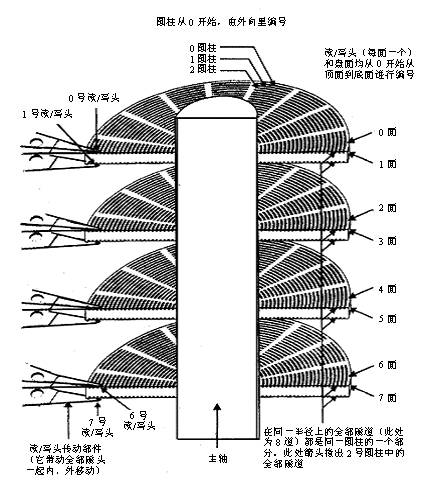
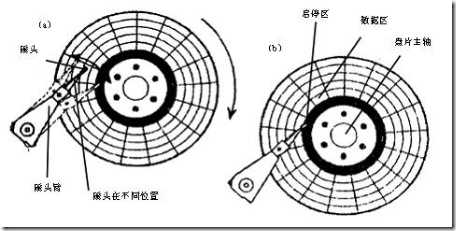
所以一次访盘请求(读/写)完成过程由三个动作组成:
- 寻道(时间):磁头移动定位到指定磁道
- 旋转延迟(时间):等待指定扇区从磁头下旋转经过
- 数据传输(时间):数据在磁盘与内存之间的实际传输
而总时间就是 寻到时间+旋转延迟+n×数据传输时间。
但是这个节点到底应该多大?虽然磁盘是以扇区为大小进行读写的(大多512b,但是有更大扇区的硬盘,比如有4k的),但是磁盘和操作系统却是用块为单位进行交互的。
块的大小必须是扇区大小的2的n次方。比如4k,一个页的大小也4k。所以我推测一个b树的节点,大概就是4k大小。
所以b树基本上可以说是为机械硬盘量身定制的,b树的层数决定了在磁盘上查找的次数,而越小的次数,带来的就是更高的效率。
然而在固态硬盘中,虽然也是以整数倍读写,但是它并不用移动磁头之类的机械操作,固态硬盘使用闪存进行存储,所以它的寻址效率和内存是一个数量级的,使用电位进行寻址,类似内存本身每一个存储空间都有一个地址,直接通过电门运算就找到那个地址了 。
但是从数据结构上来说,索引毕竟是索引,肯定要比遍历快很多,所以虽然ssd的随机读写很快,但是毕竟没有内存快。所以使用b树还是很有意义,再加上很多优化的算法都是基于磁盘的,这种历史包袱也不是说丢就能丢的。
因为旋转的受限,所以就算是顺序读写,固态硬盘也要比机械硬盘快,但是快的不是特别明显,毕竟如果是顺序读写,都可以有预判,可以提前做优化。这也就是为什么即使是固态硬盘本身,顺序读也要比随机读快。
那既然提到了b树,就在顺便提提b+树
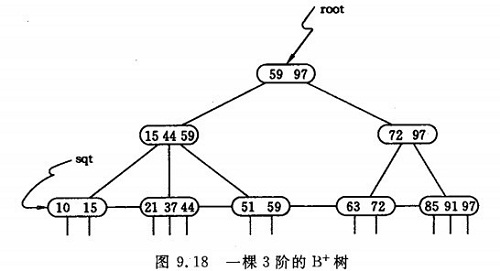
b+树与b树的区别是,叶子节点包含了全部关键字信息。而非叶子节点则可以看作是索引部分,结点中仅含有子树最大值(或最小)关键字。而且b+树都不能算严格意义上的树了。
这其中的区别是,在b树中,非叶子节点和叶子节点的区别并不大,非叶子节点即作为索引又作为存储关键字的节点,只不过叶子节点就算是到头没有子树而已。而在b+树中,非叶子节点,就作为索引来存储最大(最小)的关键字,而叶子节点,就作为存储关键字的部分,这样b+树的索引能存储更多的索引。叶子节点也能存储更多的key,平均下来,查找次数要比b树少。而且因为它的叶子节点被串了起来,所以范围查找和遍历的效率更高。
但B树包含每个键的数据,频繁访问的节点可以更接近根节点,从而更快速地访问,而且b树要比b+树在实现上简单。
相关资料: