CPU
问题:linux有哪些用来查看CPU的命令?
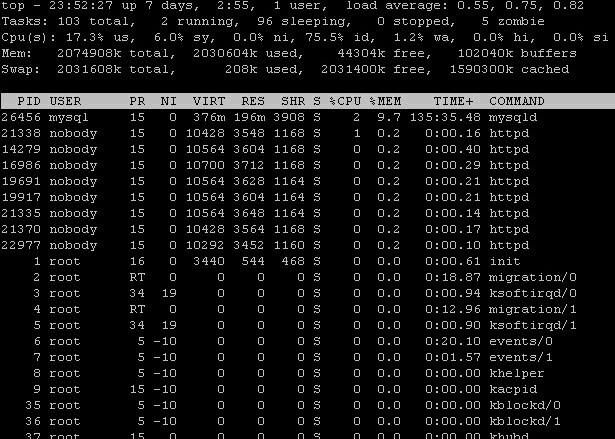
命令:top
简介: 查看系统运行的基本状况
命令:mpstat -P ALL 1
简介: 每个CPU的占用情况

这些参数包括:
- User —— 运行的应用程序
- System —— 操作系统
- Interrupt —— 硬件中断
- Wait —— 等待I/O操作的完成
- Steal —— 与虚拟机无关的周期
- Idle —— 未进行任何作业
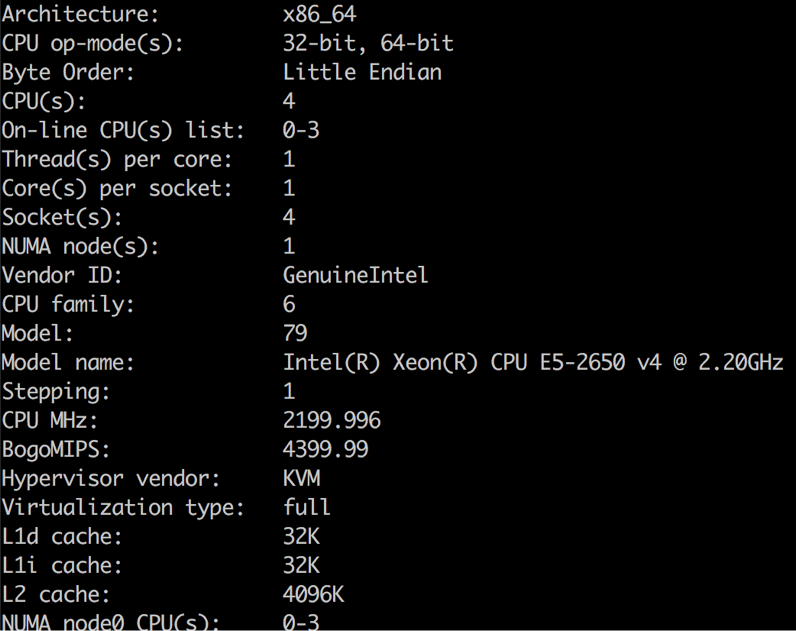
命令: lscpu
简介: 查看CPU信息
问题: cpu使用率是如何计算的?
此例子来源于《编程之美》,简单的来说,cpu使用率就是程序在运行期间实时占用的CPU百分比。如果你想让你的cpu使用率图水平保持为50%(图中为双核cpu所以是25%)。
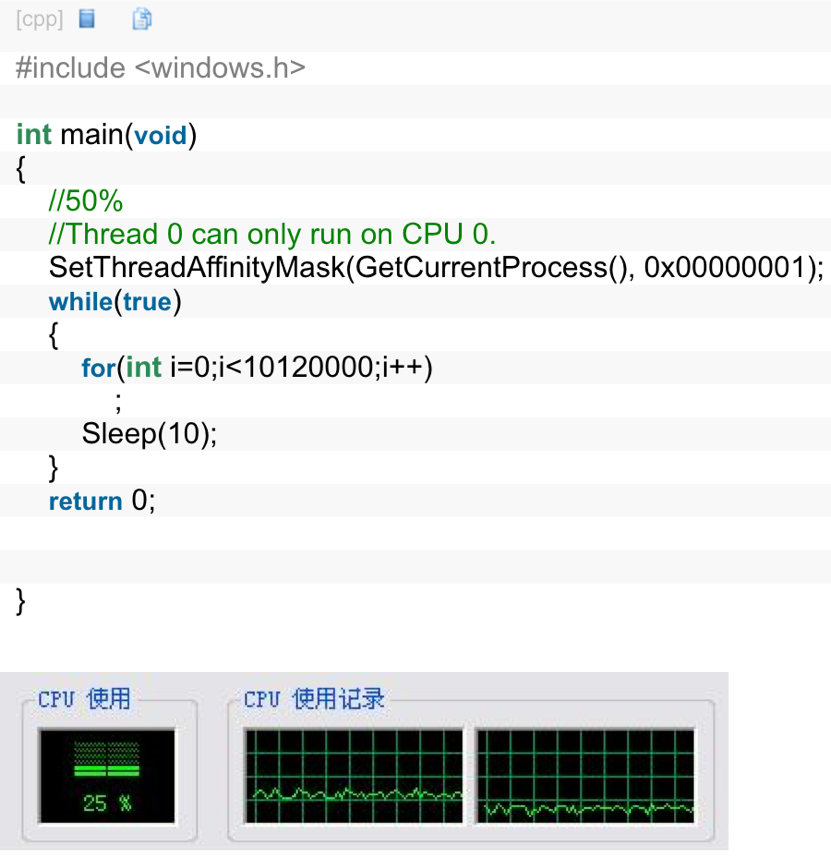
分析:
- for循环对应的汇编语句大概5条。
- 现代cpu每个时钟周期可执行两条以上的代码。
- cpu频率:2.53GHZ
- (2520 000 000*2)/5=1012000000(每秒可以执行循环次数)
- 10ms接近windows的一次调度时间。
问题:cpu使用率过高如何定位到相关线程?
TOP命令查找进程PID
top -H -p pid -d 1 -n3 查看进程包含的线程cpu使用情况。
jstack pid |grep (16进制的thread_id )-a 30
问题: cpu负载是什么?
简单来说 表示的是一段时间内正在使用和等待使用CPU的平均任务数,如果把cpu想象成一座大桥,则当 系统负载为0,意味着大桥上一辆车也没有。
当系统负载为0.5,意味着大桥一半的路段有车。当系统负载为1.0,意味着大桥的所有路段都有车。
单核cpu负载到1.7是什么意思?
还是上面那个例子,系统负荷为1.7,意味着车辆太多了,大桥已经被占满了(100%),后面等着上桥的车辆为桥面车辆的70%
多核cpu的负载是怎么计算的?
继续上面的例子, 双核CPU负载2.0,表示一个双通道的桥,两条通道都占满了桥。
问题:cpu负载为什么会飙高?
首先要指出,系统平均负载就是处于运行状态和不可中断睡眠状态的进程的平均数。
可运行主要指:运行态,占用CPU,或就绪态,等待CPU调度, 不可中断主要指:阻塞,正在等待I/O。
所以可以推断出cpu负载飙高的原因有:CPU本身处理太多任务,再加上软中断和上下文切换太频繁导致负载高;磁盘等不可中断睡眠(uninterruptible sleep)太多导致CPU负载高。
问题:CPU负载和使用率之间有什么关联关系吗?
- CPU使用率:显示的是程序在运行期间实时占用的CPU百分比。
- CPU负载: 显示的是一段时间内正在使用和等待使用CPU的平均任务数。
所以能得出以下结论:
- 通常情况,cpu负载高利用率也高。
- 利用率高但是负载低,说明程序本身有太占用cpu的操作。
- 负载高利用率低,说明等待执行的任务很多。而且cpu根本没用工作。
问题: falcon上有哪些常见的监控cpu的指标?
falcon是小米开发的一个开源的监控系统。
- cpu.idle 除io外的等待时间,这个值越大,表示CPU越空闲
- cpu.busy 等于 1 - cpu.idle
- cpu.iowait CPU空闲、并且有仍未完成的I/O请求(用于等待IO完成的CPU时间)
- cpu.steal 同一宿主机上的其他vm所占用的超出指定cpu配额的程度
- cpu.switches 上下文切换
- cpu.system CPU发生在系统级别执行的百分比
- cpu.user CPU发生在应用程序执行的百分比
- load.1minPerCPU cpu负载 1min
- load.5minPerCPU cpu负载 5min
- load.15minPerCPU cpu负载 15min
如果一个线程在等待io操作,那么cpu还会分配时间片给该线程吗?
不会
那如果等待io,cpu不会分配时间片给线程,那么cpu.iowait 在指什么?
是因为进程在等io,cpu没有进程可运行。导致了cpu在进行空转。
但是这里必须要提及以下iowait到底指什么, 首先CPU等IO模型,并不是cpu不停地轮询IO,查询其是否准备好了。早期外设到内存的IO操作,都需要cpu介入,不停的轮询状态。控制io操作,这种方式被称为PIO。但后来硬件外设都引入了DMA,可以说将io操作托管给了DMA,这样只要在开始传输和传输结束的时候让CPU介入就可以了。这样减少了CPU的负担。
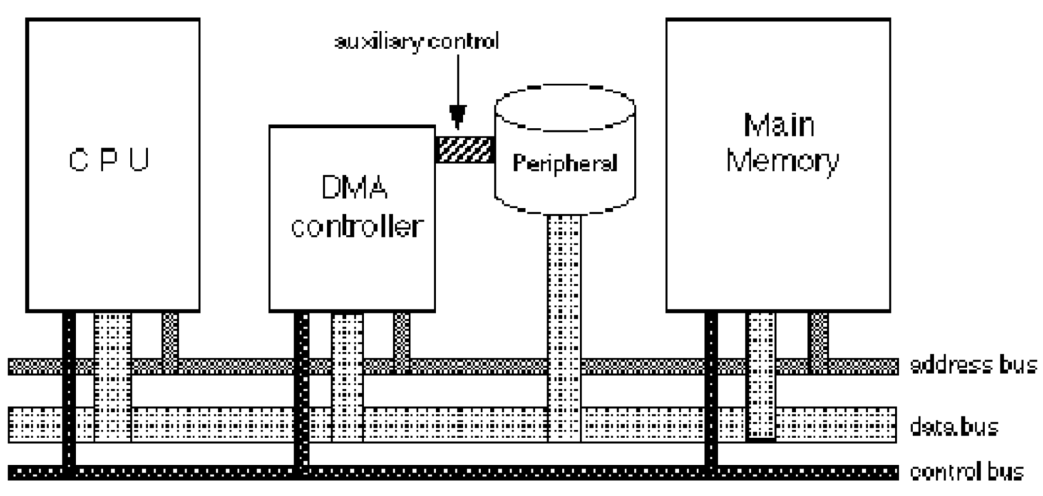
问题:什么是cpu上下文切换?
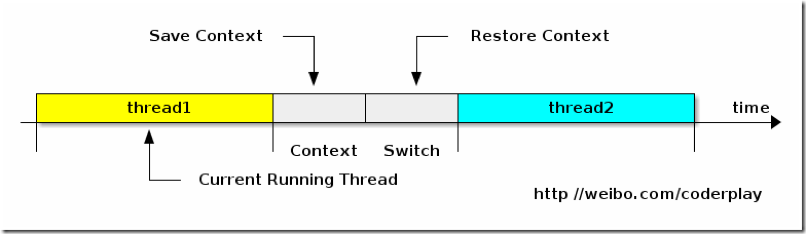
- 挂起一个进程,将这个进程在 CPU 中的状态(上下文)存储于内存中的某处,
- 在内存中检索下一个进程的上下文并将其在 CPU 的寄存器中恢复,
- 跳转到程序计数器所指向的位置(即跳转到进程被中断时的代码行),以恢复该进程。
什么时候CPU会上下文切换?
- 时间片用完,CPU 正常调度下一个任务;
- 被其它优先级更高的任务抢占
- 执行任务碰到 I/O 阻塞,挂起当前任务,切换到下一个任务
- 用户代码主动挂起当前任务让出 CPU
- 多任务抢占资源,由于没有抢到被挂起
- 硬件中断
比较常见的真实案列:
- 大量的线程(任务)
- 加锁共享资源竞争
内存
问题:用来查看内存的命令有哪些?
free -m
简介:按照兆字节,统计内存信息。包括整个内存大小。

- Swap: 虚拟内存大小,如果使用了虚拟内存,可能系统的物理内存比较吃紧。
- used: 已使用的物理内存大小
- free: 空闲的物理内存大小
- shared: 已经被废弃的共享内存,总是0
- buff: 块设备的读写缓冲区
- cache: 用来缓存文件,提高读取效率
问题:buff和cache有什么区别?
- buffer是因为减少调用次数,集中调用,提高系统性能。
- cache是将读取过的数据保存起来,重新读取时若命中就不去读取硬盘,局部性原理。
问题:有哪些常见的引发内存报警的异常?
- 内存泄露导致的内存空间不足
- 突如其来的流量导致内存被打满
- 申请大对象
问题:falcon上有哪些常见的监控内存的指标?
- mem.memused.percent 使用内存占比
- mem.memfree.percent 空闲内存占比
- mem.memused 内存使用大小
- mem.swapused.percent 使用的虚拟内存占比
- mem.swapfree.percent 虚拟内存空闲百分比
- mdm.swapused 虚拟内存使用大小
磁盘
问题:linux有哪些常用的查看磁盘的命令?
df -h查看磁盘整体使用情况du -h查看磁盘目录使用情况
问题:有哪些常见的引发磁盘报警的异常?
根据经验,大部分磁盘报警的原因是磁盘被打满。
- 新需求的日志
- 大流量的服务
- 修改部署脚本后发布的新机器
问题:磁盘被写满了会有什么风险?
- 无法写入日志
- 如果系统的物理内存用光了,则会用到swap。系统就会跑得很慢,但仍能运行;
- 如果Swap空间用光了,那么系统就会发生错误。
问题:那么日志把磁盘打满了会影响到swap区吗?
不会!因为磁盘是分区隔离的!
falcon上有哪些常见的监控磁盘的指标?
df.statistics.total磁盘总大小df.statistics.used磁盘已使用大小
网络
linux有哪些常用的查看网络的命令?
ping 10.7.177.104
网络是否连通(没有端口, 它是网络层的,端口是传输层的概念)
telnet 10.150.159.71 5516
查看端口是否畅通
netstat -a
列出所有当前链接
查看 tcp各个状态个数
netstat -n | awk '/^tcp/ {++S[$NF]} END {for(key in S) print key,"\t",S[key]}'
有哪些常见的网络故障?
- 异常流量
- 链接失败
- 网络延迟
- 网络丢包
问题:什么是网络丢包,为什么会网络丢包?
网络丢包分为物理丢包和逻辑丢包,物理丢包指的是底层传输导致的无法接收数据包,tcp丢包指的是TCP协议栈丢包。
问题:如何统计物理丢包?
使用ifconfig就能看到物理丢包。
网络的指标有哪些?
net.if.in.bps/iface=eth0 网卡入流量
net.if.out.bps/iface=eth0 网卡出流量
snmp.Tcp.ActiveOpens Tcp 主动连接的发送次数
snmp.Tcp.PassiveOpens Tcp listen状态被动打开的次数
snmp.Tcp.CurrEstab 当前已建立的Tcp连接数
snmp.Tcp.InSegs 收到数据包个数
snmp.Tcp.OutSegs 发送数据包个数
snmp.Tcp.InErrs: 收到有问题的数据包个数
snmp.Tcp.AttemptFails tcp 连接尝试失败数
snmp.Tcp.EstabResets tcp 连接被resets次数
snmp.Tcp.RetransSegs tcp 重传包个数
如何在falcon上看到逻辑丢包数?
- TcpExt.TCPLoss (tcp协议栈丢失数据包而进行恢复的次数,此时falcon-agent所在主机为接收方)
- TcpExt.TCPTimeouts (tcp数据在指定时间内没有受到应答ack而超时的次数,此时falcon-agent所在主机为发送方)
- TcpExt.TCPLossFailures (tcp协议栈丢失数据包进行恢复失败的次数)
- TcpExt.TcpFastRetrans (tcp快速重传的次数)
虚拟机上的服务,哪些指标会相互影响?
cpu,磁盘,网络都是共享的,会产生影响,内存是独享的
虚拟机上的服务,为什么相互会影响到磁盘?
磁盘只限制了大小,宿主机是公用磁盘的,某的vm写入量大,必然会影响到其它vm的磁盘性能
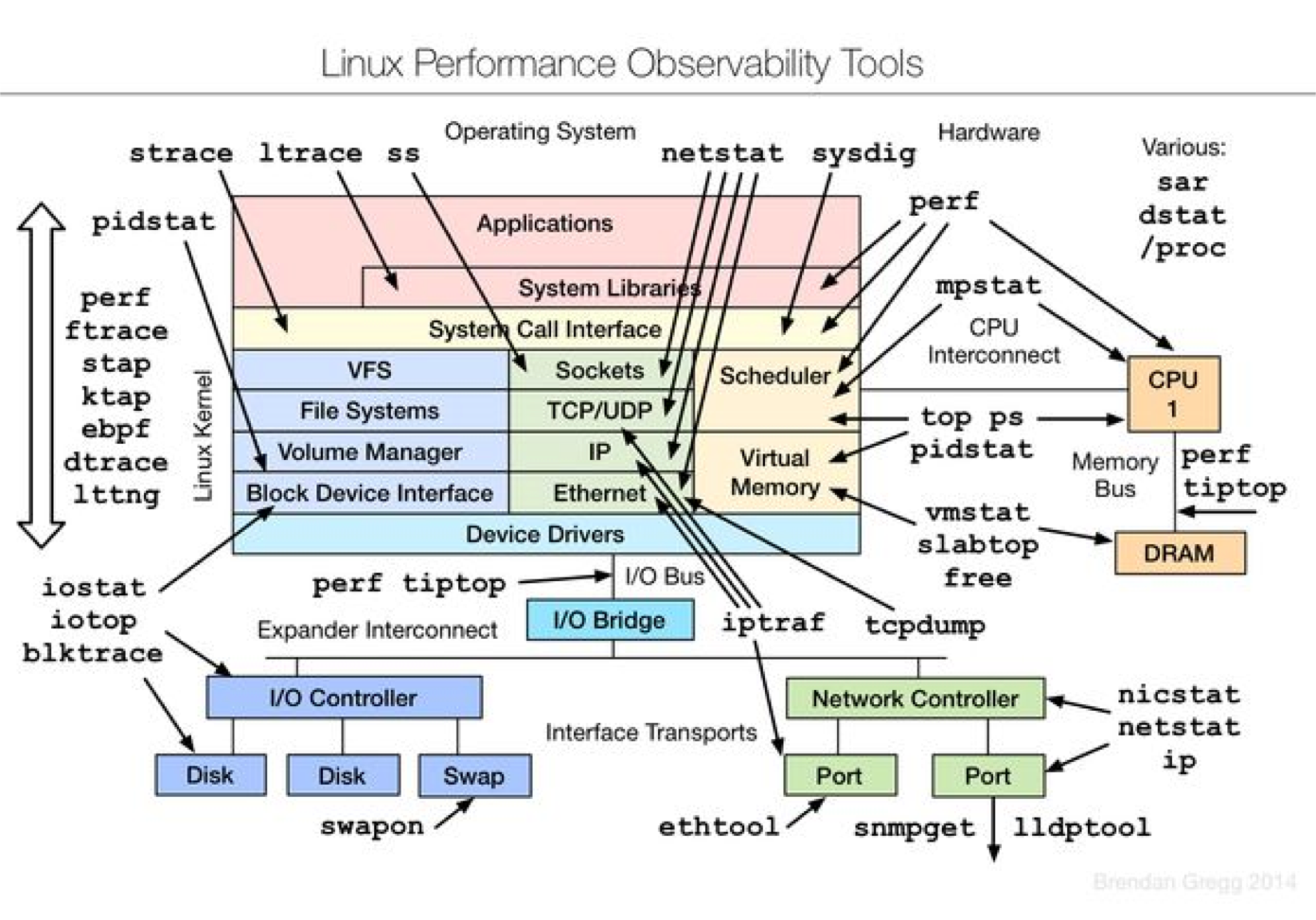
附录:
linux命令对应的系统层: