有一个经典的交互场景,A让B做一件事情,然后B做完了再告诉A。
1 | BResponse bResponse = unBlockCallB(); |
这种交互最简单的方式是使用阻塞。也就是说在B做这件事的时候,A什么也不做,干干的等它做完,再继续执行。这种简单又实用,但是我们为了效率,觉得让A这么白白的等着太浪费了。所以决定把A对B的调用做成非阻塞的,也就是说A在调用B的时候,会马上返回。那么一个问题是,B在做完之后,如何通知给A?
轮询
一种方式是A其实专门就有一部分代码轮询这个返回结果,另一部分专门做别的事情:
1 | unBlockCallB(); |
之所以要轮询,是因为你还要在此上下文内,在得到B的返回结果之后做一些事情。否则你调用非阻塞就可以了,根本不用关心它返回了什么。
但是按照上面的例子,轮询非阻塞真的得不偿失,不如直接调用阻塞,因为它除了“处理B的返回结果”之外,也并没有什么可做。
而且一般的程序是不会有什么奇怪的逻辑,会在正常的流程中,专门隔一段时间去单独检查某个非阻塞调用。
常见的实用场景是:同时监听多个非阻塞调用。
1 | for(fun in funcList){ |
不过这段代码看上去有点蠢,如果是这样,不如阻塞直到有某个非阻塞有返回,而不是不停的轮询。
1 | while(true){ |
这个例子是不是让你想起了select系统调用:
1 | while true { |
当然提到select,就不得不提到epoll了,
1 | while true { |
epoll有一个“更好”的代理,每次返回给你一个准备好的io组,让你直接处理这些io组。
多路复用就是这样一个模型,轮询多个非阻塞IO,无论是可读(read),还是可写(write)。
编程领域中,这些轮询的模型都非常相近,比如很多语言都会使用的事件处理机制:EventLoop
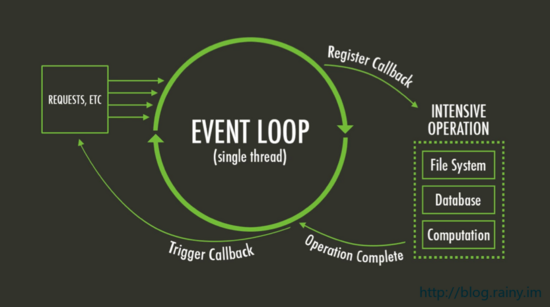
而且你发现,这些轮询的程序,基本看上去就像是一个服务(死循环)。
中断
上面提到处理方式是要自己主动的去轮询,是否有消息。这貌似和我们生活常识理解相违背,比如你不会每时每刻不停的刷微信,看有没有人给你回复信息(除非那个人是你的女神)。真实情况是,你在给别人发送完消息之后,去干别的事情,然后别人发送消息给你的时候,要么是有一个铃声,要么是有一个震动,你会停下手头的事去看消息,消息处理完之后,再来做手头的事。
但是这种场景在代码中如何实现?
这一点很神奇,你的代码在执行的时候,其实是这样的:
1 | 1 |
按照顺序一一执行。比如说你非阻塞的的调用了B,而B会在这一条条代码中的某一条执行的时候通知你了。那么问题是当A受到通知的时候(假设有通知这种方式,稍后我们再讨论有哪些实现通知的方式),A要如何处理这个通知?
这里就需要一个异常处理机制。
当然这里所说的异常机制,并不指你代码中try..catch。这是指非正常的程序流程,也就是说,你的程序会在某个时间点,收到一个通知,然后它不得不将此时的上下文压栈,然后去处理通知,等处理完通知之后,再回到之前的上下文继续执行。我们在为linux编写信号的回调函数的时候,就是这种方式。
这种方式,你完全不知道会什么时候通知你,所以本身用这种模型的程序,很难会是一个服务,或者说这种通知不是很频繁,很偶尔,有点接收特殊消息的感觉,比如一些优先级的高的程序,比如键盘中断,EXIT,退出程序。
在《深入理解操作系统中》,提到这种异常流程的处理方式。它类似于调用过程,都是将上下文压栈。而且异常处理机制一般是指硬件和操作系统之间的交互。而上面提到的信号是一种高级的异常处理机制,用于进程间通信的。
当然通知的方式可以是设置应用程序地址空间的某个变量,或者是通过信号,或者是软件中断,或应用程序执行流程之外的某个回调函数。
如果来了多个通知信号要怎么办呢?
要么是使用栈的方式,再调一次处理函数。(这要看这个信号的处理函数,是不是可重入的。一般硬件级别的处理函数,都是不可重用的)。
要么就是忽略,(你给进程发送多个同一类型的信号,后面的就会被忽略)
要么就只能阻塞到第一个消息处理完。(比如可以在前面加一个事件队列,这样就可以一个一个的处理。cpu中断屏蔽的处理方式就和这个类似。但是作为软件设计,与其在中断前加一个队列,不如直接设计成轮询的模型。)
所以在通知比较少,或者是较为底层的模型中,会使用中断,通知量较大的模型中,都会使用轮询。还有更常见的分层软件设计。内部的引擎设计是轮询。但是你在使用提供的接口时,用起来就是一个注册回调函数或者是协程,看上去很像是中断机制。
还要再谈一点更有趣的,其实底层的设计也并非都是中断设计,比如我们的网卡,在数据量小的时候,每一个数据包都会让网卡产生一个中断。随着数据量的增加,每个包都产生中断代价太大,kernel就会开始interrupt coalescing机制,让网卡做中断合并,也就是说来足够多的数据包或者等待一个timeout才会产生一个中断,kernel在响应中断时会把所有数据一起读出来处理,这样可以有效的降低中断次数。如果数据量更大的时候,既然网卡缓冲区里几乎总是有未处理的数据,那么kernel干脆会禁掉网卡的中断,切换到轮询处理的模式。
所以设计也会根据场景的不同,在中断和轮询之间切换。