锁的由来
并行的程序访问共享变量的时候,如果至少有一个访问是更新操作,就会出现问题。
书本上常常拿银行账户取款来举例子。我就不写了,因为我说道银行账户取款,你就知道我在说什么了,无非就是某个执行的上下文在执行的中途被修改了,解决这个问题的方式就是利用锁,来保证一次只允许一个线程执行该段代码。
锁的危害
n个相同的任务,如果每个任务执行的执行时间是t,那如果单线程一个一个的执行,那耗费的时间就是n*t。
但是如果交给n个线程并行执行,并且假设有足够的cpu核来保证所有的线程都同时执行,那耗费的时间就是t。
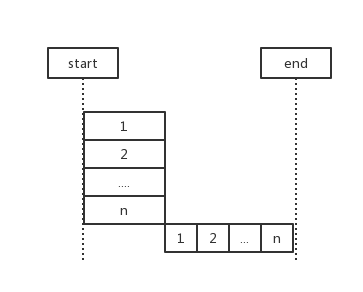
可惜事与愿违,n个任务可能要访问同一变量,所以不得不用锁把临界区锁起来,让这片区域的代码串行执行。
所以我们分开讨论,对于每个任务,可以独立执行的部分还是会并发的运行,只不过对于被锁住的临界区,不得不退化为串行代码了,这样看来,这部分时间并没有节省下来。
互斥锁
互斥锁提供最基础的锁,也被称为互斥量,可以用来限制每次只能有一个线程进入临界区。保证了一个线程独享临界区。其它线程只能阻塞直到这个锁资源被释放,获得锁的线程是随机的,也就说那些阻塞等待的执行线程,执行起来是无序的。
java中可以自己创建一个锁,来把临界区的代码锁起来,不过要记得在finally中释放这把锁,否则如果出了异常,其它线程都会阻塞在那里。:
1 | Lock lock = new ReentrantLock(); |
不过java中提供一种synchronized关键字,来修饰方法,使得这个方法,在被多个线程运行的时候,同一时间只能有一个线程进入。
1 | synchronized void f(){ … } |
需要注意的是,如果这个对象有多个synchronized方法,那么这些方法,共享一把锁。而且你要把这些方法所修改的属性设为私有变量,否则你不能阻止其他非synchronized方法的修改。
自旋锁
上面提到的这种互斥锁,线程在获取不到锁的时候,会进行阻塞,知道获得到锁才开始running,这其中有一个sleep->running的过程。还有一种写法,并不释放cpu,而是一直占用。类似于在一个死循环中一直监听cpu的状态。
所以这种自旋锁一定要是锁的获取时间非常快,而且是多核cpu,否则会很降低CPU的效率。
1 | y = Compute(my_rank); |
而且这种自旋锁的维护成本较高,一般也很少使用。
信号量
一些书籍和博客,会把信号量表示为: 互斥锁通常就是信号量值为1的简化版本。但是这个说法很有误导性,尤其是先讲互斥锁再讲信号量。
互斥锁的锁之后开锁和关锁,0~1的两种状态。仅仅是互斥,也就是说多个人获取一把锁的时候,仅仅有一个人能获得,其它人需要阻塞直到此人释放了这把锁。但问题是,之后谁获得这把锁也是随机不确定的。而且所谓的互斥锁还有一种所有权的概念,也就是你上的这把锁,只能由你自己亲自打开。所以它仅限制在构造临界区上。
而信号量本身就有通知和同步的作用。所以它能既解决了临界区的问题,又能解决了通知的问题,这个是互斥锁解决不了的。比如说现在有一个需求,需要你阻塞读取磁盘,直到有数据之后再唤醒它。
那么我们可以用信号量实现,在主线程中使用一个semaphore_decrease()因为此时的信号量0,所以它会阻塞在这。然后在读取数据完成后,semaphore_increase()
这样主线程才可以运行semaphore_decrease()使代码继续运行下去。这样一个一元信号量,互斥锁都满足不了。还有类似某个线程需要等多个线程执行完才可以继续执行。都有类似生产者消费者的同步问题,这都需要信号量。
其实信号量还有一个作用,就是限制并发,因为信号量不仅仅可以是1,比如你的信号量现在是5,那就限制只有五个线程能够获取,第六个已经没有信号可以decrease了。
所以这也就是为什么当信号量为1的时候,它看上去像是一把锁。
不过既能做临界区又能同步消息,不是一个好的设计,这也就是为什么很多人都建议不要用信号量。所以linux 的很多场景都变为使用互斥锁,需要通知的场景则改为completion variable了。