红黑树和跳跃表都是高效的数据结构,但redis的zset底层实际使用了跳跃表而非红黑树是为什么?
这篇博客的内容来自于我在公司分享的一部分内容,其目的是探讨如何对比两种数据结构?背后的原理是技术选型的思路?
当然要说明一点,要说zset是跳表也不完全合适,使用的其实是改进后的跳表,比如允许key重复。
那么如何对比两种数据结构?首先要看他们支持哪些操作,这些操作的复杂度是多少?
那对于大部分数据结构而言,它们要支持的操作无非就是增删改查,分的更细一些就是单个查找和范围查找,找最大最小之类的。那么接下来我们就分别对比下这两种数据结构,对应操作的时间复杂度是多少。
时间复杂度
讨论时间复杂度两个最常用的方法是,平均时间复杂度和最坏情况时间复杂度。
红黑树和跳跃表的插入和查找接近,都是O(lgn)级别的。
其中,红黑树在最坏情况下查找和插入是2lgN。而跳跃表最坏情况应该能达到O(n),就像遍历链表一样,所以这样单纯的看这两点。两者的差异并不大。
空间复杂度
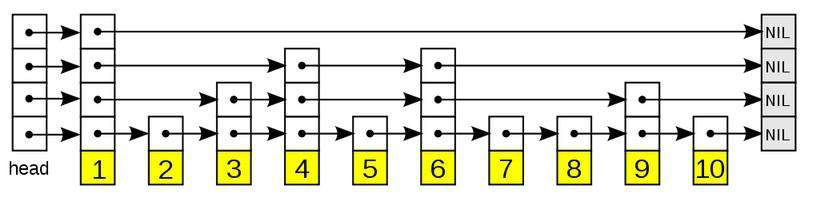
跳表的空间复杂度应该更高一点(额外空间是O(n)),毕竟它就是一个拿空间换时间的数据结构,要维护更多的指针节点。我有在网上阅读到一些人做的实验,红黑树要更省内存,而且时间比较会更快一些。但是这对于业务应用而言,都可以忽略。
硬件
这里提到硬件,主要是因为我们在选择数据结构的时候,有时候会考虑到硬件的影响因素,比如B+树更适合硬盘,因为硬盘的IO是瓶颈,B+树可以把树的高度压的很低,而且一个节点大小=innodb的一页=4个操作系统页(一页4kb)=16kb。方便IO一次载入。虽然目前看来没有必要在红黑树和跳跃表之间比较这种硬件差距,但是这样的意识还是要有的。
实现复杂度
插入
红黑树插入需要旋转和着色,实现较为复杂,如果是删除操作就更复杂了,但主要是代码上的复杂,并不是这个操作要大量的改造树,其实红黑树最多旋转三次就能达到平衡。
而跳表的插入就比普通的链表插入节点稍复杂一些。
区间查找:
红黑树的中序遍历要复杂一些,而跳跃表实现起来要更简单一些,就像遍历链表一样。
我们自己对比完之后再来看看redis作者的想法,我对一些比较关键的信息进行了翻译。
There are a few reasons:
- They are not very memory intensive.[对内存并不敏感] It’s up to you basically. Changing parameters about the probability of a node to have a given number of levels will make then less memory intensive than btrees.[控制层级参数甚至比Btree还节省内存空间]
- A sorted set is often target of many ZRANGE or ZREVRANGE operations, that is, traversing the skip list as a linked list[遍历操作可以像链表一样方便]. With this operation the cache locality of skip lists is at least as good as with other kind of balanced trees.
- They are simpler to implement, debug,and so forth. [它们实现和调试都很容易]For instance thanks to the skip list simplicity I received a patch (already in Redis master) with augmented skip lists implementing ZRANK in O(log(N)). It required little changes to the code.
About the Append Only durability & speed, I don’t think it is a good idea to optimize Redis at cost of more code and more complexity for a use case that IMHO should be rare for the Redis target (fsync() at every command). Almost no one is using this feature even with ACID SQL databases, as the performance hint is big anyway.
About threads: our experience shows that Redis is mostly I/O bound. I’m using threads to serve things from Virtual Memory. The long term solution to exploit all the cores, assuming your link is so fast that you can saturate a single core, is running multiple instances of Redis (no locks, almost fully scalable linearly with number of cores), and using the “Redis Cluster” solution that I plan to develop in the future.
所以作者的想法还是因为实现简单。不要认为能写redis的人没有复杂度这方面的考虑。
“大约10%的程序员,才能够正确地写出二分查找。尽管第一个二分查找程序于1946年就公布了,但是第一个没有bug的程序在1962年才出现”-《编程珠玑》,《计算机程序设计艺术》。(溢出的问题)
所以顶级程序员也有降低复杂度的诉求。
按照这个思路我们可以逆向思考一下,为啥java的hashmap,要用红黑树而不是用跳跃表。其实最后的原因可能多种多样,甚至是历史原因。但不要忘了,思考这个问题的根本目的其实是为了加强技术选型的思维方式。