最近我在从python的开发转向java,打算在转移技术栈的时候,通过比较python与java,去更深刻的理解动态语言与静态语言的优势与劣势,从而在工作中有效的搭配。所以接下来很长一段时间,我都会坚持写一些关于java和python两者比较的博客,当然刚入门java,自然写的东西就比较“弱智”了,但这一步早晚都要走的,先勇于接受吧。。
我一开始在想,如何入手java,从什么语言基础或者是设计模式,我觉得都不是好的方式,毕竟已经对这些比较熟了。静态语言本来也没有什么奇技淫巧,就算有也百八十年用不到,框架的话也不用急着去看,因为用着用着该会的也就会了。一堆不知道怎么用的规则更没必要记了,再加上自己也想让自己的水平提升一个台阶,所以我想要不就从java并行程序设计开始吧。
这篇博客我要写一些关于Future对象的东西。
java中的Future
你在一开始学习java多线程的时候,书上都会告诉你一个简单的例子,就是先创建一个任务,这个任务对象继承一个Runnable接口,并且实现了其中的run方法。
1 | public class Task implements Runnable{ |
然后你就可以用线程来执行此任务,比如直接提交给一个Thread的构造函数。
1 | Thread t = new Thread(new Task()); |
或者直接扔给执行器(Executor)。
1 | ExecutorService exec = Executors.newCachedThreadPool(); |
这看上去没什么问题,Executor负责管理你的线程,你的任务得以“异步执行”,但是好在这仅仅是一个打印,如果你的任务最终要获得某种结果,那Runnable就不能满足你的需求了。这个时候你可以选择让任务实现Callable接口,可以满足这个场景。
1 | public class Task implements Callable<String>{ |
看到Callables实际上是一个泛型接口,而我们能在线程执行结束后,从Futrue对象中获得最后的结果。
这个Futrue对象看着好眼熟,在用python的异步web框架-tornado的开发中,你也会看到这个对象,但大多数是抛异常的时候才会看见,因为tornado的使用协程隐藏了对这个对象的使用。这个我会在后面提到,下面先来分析下这个Future对象是个啥。
首先这个Future类提供这样几个方法。get用来获取结果,isDone用来查询该Future是否已经完成。但要注意的是,如果这个future还没有结果,那get方法就会阻塞在那里。
之后我查阅了一些资料,我找到了Future的大概实现原理。
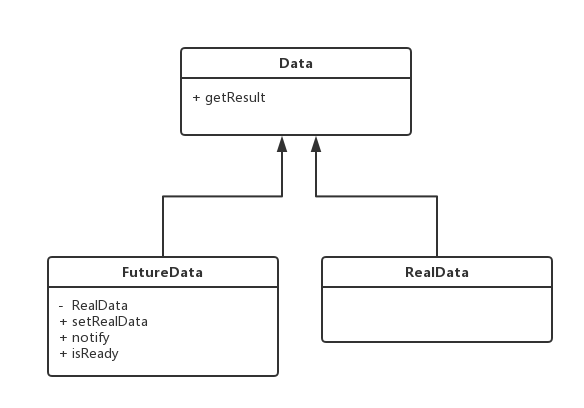
其实最终的数据被我们包装在RealData中,Future对象算是RealData的代理类。它和RealData都实现了Data接口,可以通过getResult获取最终的结果。
RealData的getResult调用会返回真实的最重结果。FutureData则自己有一个属性是RealData类型的,它一开始是空的,当Executor执行完成,就会调用FutreData的setRealData初始化这个属性,并将它的isReady属性设置为true,并对它的getResult做一次notify,所以如果Future的数据没有准备好,则调用FutureData的getResult则会阻塞直到数据isReady为True,然后它就调用了RealData的getResult。
现在你应该明白它为啥叫Future了吧,因为你在将任务扔给Executor的时候,它会立即返回,但是里面却还没有线程执行的最后结果,等到线程结束后,里面才会有结果,这就好像你一开始就拿到了“未来”一样。
或者也可以说并发程序设计中,有一种设计模式,叫Future模式。
tornado中的Futrue
那么接下来我们再来看看之前提到的tornado中的future。
tornado的future在tornado.concurrent这个库中,如果你使用tornado时,不使用它的“协程”,那只能使用讨厌的回调方式来执行异步结果返回后的代码,如果是回调套回调,那更加的令人头疼。
1 |
|
我们在tornado中使用协程的调用方式,其实就返回了一个Future对象,但是与刚才java中的例子不同的是,我们使用了yield,既返回了Future,又让出了程序的执行权。这点非常重要,因为刚才java的例子,我们的程序一直阻塞在future对象的get方法一直到它有返回,但是我们在tornado中不能这样,因为tornado是单线程的epoll,任何一个阻塞都会使整个服务卡死在那。所以我们在yield返回future之后,这个future对象被扔给了ioloop,并且程序的控制权也交给了ioloop,等到这个异步调用处理完之后,ioloop会把结果通过set_result写入Future对象,然后你的handler被send了future对象的get_result,程序的控制权又交给了你的handler,程序就能继续执行下去了。所以实际上程序也是堵塞的,不过那是对你的handler而言,阻塞在那里,等待结果返回。
1 | client = tornado.httpclient.AsyncHTTPClient() |
而且tornado提供一个return_future函数,它实际上是一个装饰器,也就是说它接受的参数是一个函数(回调函数),它
能把你的这个回调函数,封装成一个future对象后返回。
pyhton中的futrue
在python3.2及后续版本中,已经加入了Future,就在concurrent.futures模块中。
官网文档中有一个简单的例子使用futures来做一个简单的并行爬虫。
1 | import concurrent.futures |
可以看到和Java没什么两样。futures.as_completed函数会持续阻塞,直到有futrue完工或者取消。然后,就会把future返回给调用者。