这篇博客,我早就想写了,结果一直拖到现在(快一年),一方面是这篇博客涉及的知识会比较多,“完美主义拖延症”搞得我一直没有去写。但是现在虽然写完了,很多细节我依旧不是很清楚。
这里主要提以下几点:
- epoll是一个什么样的模型,它和其它的io多路复用,比如select poll有什么不同。
- 相比与多进程和多线程的web服务设计,它好在哪。
- 写写在python编程中使用tornado注意的事项。
- 写一些关于epoll调用的细节内容。包括水平触发和边缘触发等等。
基本概念
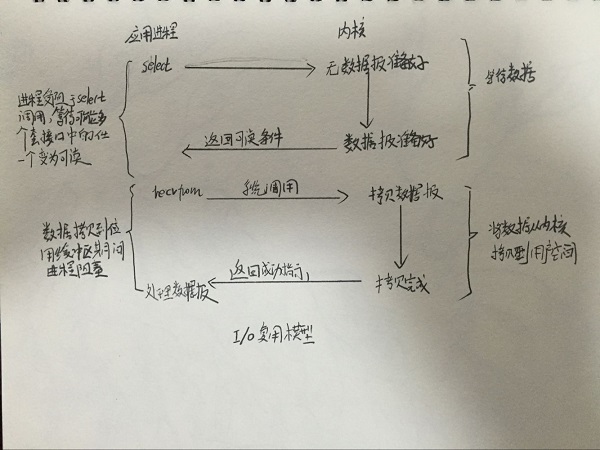
epoll是linux非常实用的linuxio模型。我们python常使用的web框架tornado,就是使用了epoll。nginx服务器,本身也使用了epoll(虽然其实现还带有复杂的worker之类)。之所以使用epoll,是因为epoll非常适合处理多个io的读写事件处理。而web服务器的本质,就是处理网络io。
《unix网络编程》,一共提到五种io模型:
- 阻塞IO模型
- 非阻塞IO模型
- IO复用模型
- 信号驱动IO
- 异步IO模型
其中IO复用模型,就是指一次可以监听多个io事件。一开始的select模型,年代比较早,实现的也比较简单。被称为忙轮询,意思就是它会同时监听n个io,并阻塞在这里。当一个io事件发生时,它会去轮询每一个io,将已经准备好的io放到一个临时队列中。这样再依次操作每一个准备好的事件io。处理完之后,在进行阻塞等待下一次io事件,整个程序就是在这样的死循环中进行的。
此时你应该发现select的缺点,首先就是它只知道有io事件准备好了,并不知道是哪几个io事件准备好了,所以它要轮询每一个io。而且select监听的fd还是有个数限制。应该是1024。
后来又开发出来一个poll的东西,在fd上没有了限制。还有一些数据结构的使用上不同,除此之外,select并无什么区别。
再后来,才有了epoll,与select和poll不同的是,它在等待n个io时,每次出现io事件时,它都能直接能从一个队列中获得已经准备好的io,而它直接在这些等待好的io中处理就好了。之所以能够这样,是因为epoll的在底层已经实现了事件机制,包括两个队列,一个软中断队列和就绪队列。
实际上这点非常有意思,我们总是在信号通知和轮询之间迂回,比如对于比较少的io,那么信号通知就非常好了,但是如果大量的信号,你还是需要一个队列来存放这些信号,然后处理它们,这有和轮询没什么差别,还复杂了模型,增加了资源,不如直接轮询。
而且你发现,epoll适合这种虽然要监听n个io,但并不是同一时刻,每个io都很活跃的模型,否则相当于每次都返回了整个io,在轮询处理,这样epoll反而退化成poll了。
还有就是《unix网络编程》中,把前四种模型统称为同步io,只有第五种,才称其为异步io。但实际上没有必要迷信于此。
这里的异步io,只是指操作系统级别的异步io,也就是等到数据从内核缓冲区读到用户缓冲区了之后,才通知用户进程。
但实际上,即使没有os级别的异步io,我们仍然有大量的进程级别的异步io可用。
类比多进程和多线程的
多进程
很早以前,linux下的web服务器,都是靠进程来维持的,也就是来一个请求连接,prefork一个进程,虽然prefork出来的进程,代价并不高(包括一系列copy on write技术),而且web服务都是有进程池的,不会来一个进程就copy一个进程,但是对于大量的请求连接来说,进程还是有点太占内存,太非资源,太重了。
当然以上的大量,主要是指解决类似c10k这样的问题。否则对于每秒几十几百个连接,prefork进程完全可以胜任。python的web经典框架flask,最常见的部署方式,就是使用uWSGI,开n个进程池。
多线程
多线程应该是java,c#这样的语言,最常使用的web部署模型了,每一个处理连接,对应一个线程,这样堵塞处理(比如io)并不会阻塞服务器,整个服务依旧正常。而且线程比进程占用的资源轻多了。虽然有锁的问题,但线程始终是web服务最常用的处理方式。但问题是,多线程仍然无法解决c10k问题。
这个就有趣了,你去网上看“一些人的评论,一个线程8M内存空间。10K个线程就是80G,这样内存就爆掉了”。
这个说法是错误的,因为linux的栈是用过缺页分配内存的,http://www.cnblogs.com/zhaoyl/p/3695517.html,所以8M是上线了。真实的损耗也就比需要的内存稍微大一些。
而且在32位机器上,瓶颈可能都不是线程大小,而是地址空间,32位的系统,虚拟内存空间是4G,其中1G是内核空间用户不可见,真正可以使用的内存空间大小是3G,所以假设线程数N,则N8M < 31024M一定要成立。
所以线程的消耗真实来源于线程的来回切换。
而epoll的控制,就不存在这种阻塞io的上下文切换。首先我们没有等到数据直到它可读,还有良好的通知系统告诉我们哪些io可读。
这里需要提一点是,早期的linux,线程确实是“假线程”,对于内核而言,它还是进程。但是2.6之后,就有了NPTL等一系列的线程技术,线程也比原来高效多了。
还有一点需要注意的是,很多人都对单线程报以一种错误的认知,比如它们觉得多线程的执行要快些,但实际上,在一个核中,只要没有堵塞操作,那么多线程和单线程的效果是一样的。因为你任务切的再细,处理花费的总时间也不会减小,一个核执行了的顺序肯定是线性的。而且都说了我们使用了epoll,io并不会阻塞。多线程的优势是可以利用多核,但是我们python的多线程并不支持多核,而且我们普遍的做法是每个核对应一个进程,这样利用多核的问题也解决了。
tornado中的注意事项
前面提到了tornado底层使用的就是epoll。首先你要明白tornado之前被设计出来是为了解决c10k问题,本质是用来处理大量的请求连接。所以它是轻业务的,所以你写的服务偏于业务,那真的不适合用tornado,除非你能控制好服务不被阻塞。否则一个阻塞的地方,将导致你整个服务被阻塞。
我们一般的部署方式也是一个内核中跑一个tornado服务,前面再挡一个nginx负载,之所以不使用tornado自带的多process,是因为这n个process共享主控的资源,这在打日志和获取数据库连接的时候,都会出现些小问题。
前面提到的不让服务阻塞,就是要活用异步库,比如tornado自带的http异步客户端。(其本质就是向ioloop中扔了一个异步请求)。但是这也暴露出tornado的缺点,那就是写起服务来麻烦的要死,也不便于调试,你要考虑各种异步的处理方式,早期的时候,gen.task,回调套回调的方式,简直就要逼疯你。后来tornado引入了协程的思想。这样可以用同步的思维写出异步的代码。
所以说tonrado好的一点,就是它作为一个web服务出现,隐藏了对epoll的调用,而且甚至提供了一些机制,让你连回调都不用写。
更细节的内容
水平和边缘触发
epoll常常会引入两个名词,水平触发和边沿触发。这两个名词应该来源于比较底层的信号中断(比如单片机),边沿触发就好像从0~1发生了变化,但是水平触发好比一只在发送1这个信号。
可以用信件的通知,来比较这两种触发:
ET (Edge Triggered) 边沿触发: 来了信件,指示板上的灯只闪一下。
LT (Level Triggered) 水平触发,来了信件,指示板上的灯一直亮着,直到信箱中的信全部被取走。
你会发现水平触发要安全一些,但是效率就没有边缘触发那么高了。而且你要想使用边缘触发,代码的处理逻辑也会复杂很多,如果我没记错的话,tornado就使用的水平触发,而nginx就使用的边缘触发。
阻塞和非阻塞
io操作一般分为读和写,当你在读取缓冲区的时候,缓冲区为空时,此操作会阻塞在这个fd上造成饥饿,而当你在写缓存区的时候,缓冲区满了,那么这个时候也会发生阻塞。
而且还要区分设备,read函数只是一个通用的读文件设备的接口。是否阻塞需要由设备的属性和设定所决定。一般来说,读字符终端、网络的socket描述字,管道文件等,这些文件的缺省read都是阻塞的方式。如果是读磁盘上的文件,一般不会是阻塞方式的。但使用锁和fcntl设置取消文件O_NOBLOCK状态,也会产生阻塞的read效果。
这里你要理解select和epoll,只是告诉你这个IO可读,但并不代表它就一定能读。也就是说,可读和读是两个不同的系统调用。
比如计算机常见的惊群现象,再比如校验错误后被丢弃的字节,都会导致这个“可读”的字节,实际上并没有数据能读。这样你如果使用了阻塞io,那就阻塞在这里了。
还有写操作,告诉你可写,但是如果缓冲区满了,一样会阻塞。
这也就是为什么,I/O多路复用绝大部分时候是和非阻塞的socket联合使用,你要使用阻塞的可以么?可以!但是你要自己想办法处理上面提到的这些问题。